Personal data detection and discovery
Personal data discovery and detection are two related activities that let you know where in your systems personal data is, how it flows, and whether it’s protected the way it should be.
Both “personal data discovery” and “personal data detection” serve the same goal: that is, preventing misuse and leaks of data that needs to be protected. These two practices are however different in how and when they’re applied.
Personal data discovery
Personal data discovery is the more strategic of the two practices. It’s a part of the general data discovery process in the scope of data governance. It involves upfront cataloguing (a.k.a. data inventory) of all the data repositories that you have, including databases (structured sources) and files (unstructured sources), as well as data flows within, into, and outside your company’s network.
As a result, you gain a general understanding of where personal data originates, how it is protected while in your possession, and where it is intended to go. This understanding is a core prerequisite for effective data protection overall, as well as for enabling specific tasks such as satisfying the Right to Be Forgotten (RTBF) requests.
As an engineer, how would you approach structured data discovery? You would need to scan both your on-premises and cloud-based infrastructure to locate all databases. This includes databases in specialized services like Amazon RDS and those installed inside more general-purpose compute environments like Amazon EC2. Once you’ve cataloged the databases, you would review each SQL table (or NoSQL collection) individually to classify the data it contains. The categories for classification are up to you, but the goal of this step is to isolate the most sensitive data that requires prioritized protection.
Discovering the data that you know about is easy. The hard part is discovering the data that you didn’t know about.
Personal data detection
Personal data detection is an operational practice of monitoring personal data and ensuring that none of it remains unprotected in order to prevent data leaks. In a way, it’s continuously challenging the results of personal data discovery.
If you were absolutely sure that data in your systems flows exactly the way you think it is based on your discovery work, and data flows never changed, personal data detection would be redundant. However, in reality, as your systems evolve, there will always be changes to what data you get hold of and how data flows through them, and you need a way to make sure that personal data is protected despite these changes.
In a sense, data detection is about discovering the data that you didn’t know you had, enabling you to take protective measures quickly, and then feed the gained knowledge to the next iteration of your data discovery process.
If you’re an engineer, you’re mostly concerned with personal data detection in your day-to-day work. Has a configuration of one of your services changed that might expose personal data? Has your team introduced a new third-party API that gets more of your users’ data than it should? Hasn’t personal data started to leak into your logs and monitoring services? These are the kinds of questions that concern you as an engineer as your codebase evolves.
Where to look for personal data leaks
Avoiding data leaks is hard! This is due to the intricate nature of logs and the complexities of integrating with third-party APIs.
Logs
Logs involve vast amounts of unstructured data, making it tricky to differentiate between sensitive and non-sensitive information. Finding patterns or anomalies in this data takes time and effort. To make matters worse, developers tend to send more data to logs than necessary, sometimes unaware of the potential exposure.
Moreover, log streams are normally accessible to many parties: both humans and machines. Including sensitive data in logs increases the risk of data exposure and should therefore be avoided.
Integration with third-party APIs
Third-party APIs can add complexity as organizations often have limited control or visibility over these external services. The lack of control makes it harder to monitor and secure the data flow. Any developer can experiment with a new API at any point in time, adding to the risk. Additionally, the use of third-party APIs may involve multiple stakeholders and organizations, increasing the complexity of detecting data leaks.
How to avoid leaking sensitive data to logs
Leaking sensitive data into logs is a recurrent and intricate issue for many developers and application security teams. These leaks are often only addressed reactively, after being detected in production. Traditional tools like regular expressions and basic automation are inadequate, lacking the depth needed to fully understand the intricate data flows in applications.
Here’s a few measures that can help minimize leaking sensitive data to logs:
- Data collection and access minimization. Focus on collecting only essential data and implement stringent access controls to limit data exposure and access to necessary services only.
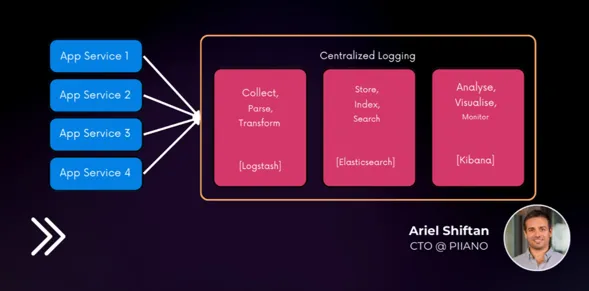
- Data redaction and centralized logging. Before you log, employ data redaction techniques such as masking, tokenization, and encryption. Utilize a unified logging system for standardized redaction and enhanced security.
- Code reviews. Manually inspect new or modified code to identify any instances where sensitive data might be inadvertently logged.
- Automated code scanning. Use automated tools to continuously scan for code vulnerabilities that could lead to unintentional logging of sensitive data.
- Continuous log monitoring. Actively monitor log outputs to quickly detect and address any unintended exposure of sensitive details.

- Role-based access control in logging. Ensure log access is strictly regulated, allowing only authorized personnel to view or modify log data.
- Prudent log retention. Store logs only as long as necessary, then securely dispose of them to eliminate the risk of lingering sensitive data.
For more guidance on preventing personal data from exposure through logs, see: